Diese Programme sind nicht Teil des "OFB Programm Pakets" und des "Gedcom Service Programm Pakets".
Ist Ihre Wunschfunktion nicht dabei, kontaktieren Sie mich. Es gibt noch weitere ca. 20 Specials als Prototypen, die hier nicht enthalten sind.Die Programme wurde mit dem Entwicklungssystem "Microsoft Visual Studio Express 2015" entwickelt.
Nur mit einer GSP bzw. OFB-Bündel Lizenz starten diese Programme.
Add2AllIndi - Zufügen Textblöcke zu allen INDI Datensätzen + ged-Datei |
|
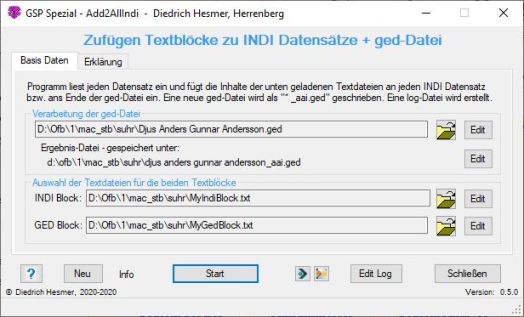
Funktionalität |
Dieses Programm ergänzt jeden INDI Datensatz einer gewählten ged-Datei mit einem festen, frei definierbaren, identischen Textblock am Ende jeden Datensatzes. Zusätzlich ermöglicht es das Einfügen eines ebenfalls festen, frei definierbaren Textblocks am Ende der ged-Datei. Diese Textblöcke können z.B. die Beschreibung des "Lieferanten" als Quelle enthalten.
Eine so präparierte ged-Datei kann nun in den eigenen Datenbestand importiert werden, ohne dass der "Lieferant" der neuen INDI Datensätze verloren geht und damit eine Rückverfolgbarkeit ermöglicht wird.
Eine weitergehende Beschreibung und das Programm finden sie im Downloadbereich.
Chars2Utf8 - Konvertierung in UTF-8 Zeichensatz |
|
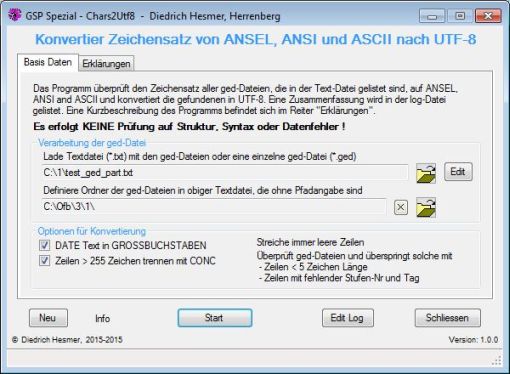
Funktionalität |
Dieses Programm überprüft die aktuelle Kodierung der ged-Datei und konvertiert Dateien mit ANSEL, ANSI oder ASCII in UTF-8 Zeichensatz. In einem Programmlauf kann eine einzelne ged-Datei oder eine ganze Gruppe von ged-Dateien verarbeitet werden.
Eine weitergehende Beschreibung und das Programm finden sie im Downloadbereich.
ConvLvl2To1 - Konvertiere definierte Stufe-2 Tags zu Stufe-1 Tags |
|
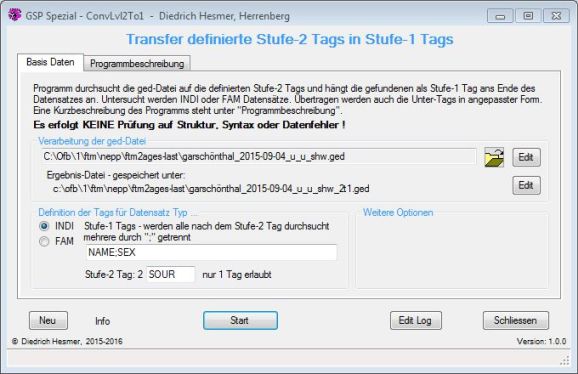
Funktionalität |
Dieses Programm durchsucht die ged-Datei auf definiertes Stufe-2 Tag unterhalb definierter Stufe-1 Tags und hängt die gefundenen als Stufe-1 Tag ans Ende des Datensatzes an. Übertragen werden auch die Unter-Tags in angepasster Form.
Nur INDI oder FAM Datensätze werden analysiert.
Eine weitergehende Beschreibung und das Programm finden sie im Downloadbereich.
CorSexHusbWife - Korrektur des SEX Wertes basierend auf HUSB und WIFE Angaben |
|
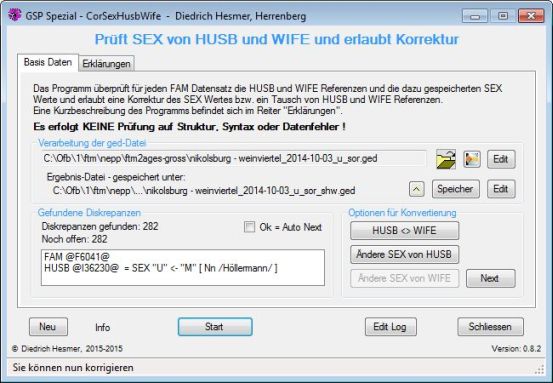
Funktionalität |
Das Programm überprüft für jeden Familien (FAM) Datensatz die HUSB und WIFE Referenzen und die dazu gespeicherten SEX Werte und erlaubt eine Korrektur des SEX Wertes bzw. ein Tausch von HUSB und WIFE Referenzen. Es können somit nur solche Personen überprüft werden, die als HUSB oder WIFE referenziert und gespeichert sind.
Eine weitergehende Beschreibung und das Programm finden sie im Downloadbereich.
DelIndiFam - Löschen von INDI + FAM Datensätzen entsprechend Datum |
|
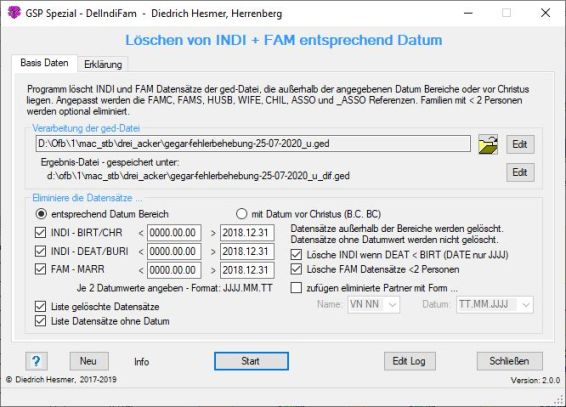
Funktionalität |
Das Programm löscht INDI und FAM Datensätze der ged-Datei, die außerhalb der angegebenen Datum Bereiche oder vor Christus liegen. Angepasst werden die FAMC, FAMS, HUSB, WIFE, CHIL, ASSO und _ASSO Referenzen. Dazu wird die ged-Datei auf Datensätze durchsucht, die auf Grund von Datum Werten zu löschen sind. Gefundene Datensätze werden gelöscht und die Referenzangaben entsprechend angepasst.
Nur INDI und FAM Datensätze werden analysiert und konvertiert.
Eine weitergehende Beschreibung und das Programm finden sie im Downloadbereich.
DelLvl2Tags - Löschen definierter Stufe-2 Tags aus Stufe-1 Tags |
|
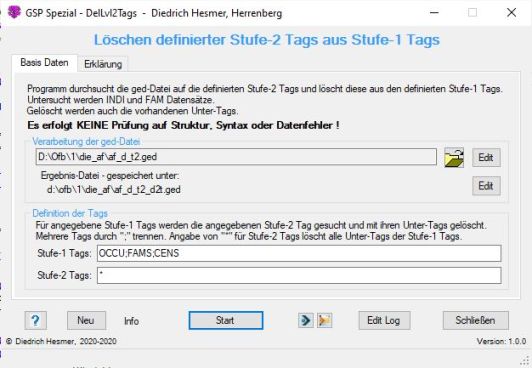
Funktionalität |
Ein Anwendungsbeispiel ist die Erstellung von Grafiken mit dem "Stammbaumdrucker", der neben dem Namen auch andere Daten mit ihren untergeordneten Daten ausgibt.
Dieses Programm durchsucht die ged-Datei auf definierte Stufe-2 Tags unterhalb definierter Stufe-1 Tags und löscht diese mitsamt ihren Unter-Tags.
Nur INDI und FAM Datensätze werden analysiert und konvertiert.
Eine weitergehende Beschreibung und das Programm finden sie im Downloadbereich.
JoinFam - uneheliche Kinder |
|
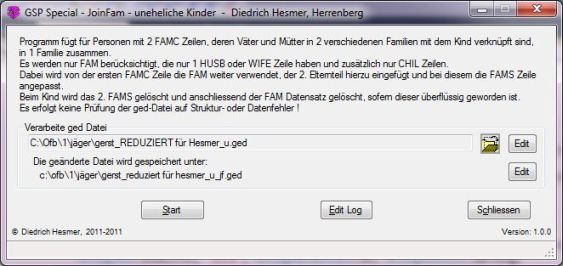
Funktionalität |
Dieses Programm führt solche Situationen nun zu 1 FAM Datensatz mit Vater, Mutter und Kind(er) zusammen und passt die notwendigen Verknüpfungen zwischen Vater und Kind bzw. Mutter und Kind entsprechend an.
Eine weitergehende Beschreibung und das Programm finden sie im Downloadbereich.
| © 2011-2023, Diedrich Hesmer, Herrenberg - letzte Änderung |
|